
Parallel Fractal Image Generation
Token-Passing Synchronization
As a first approach, we can make use of the fact that the lines are distributed among the nodes in a cyclic fashion (node 1 has lines 1, 5, 9, ...; node 2 has lines 2, 6, 10, ...; etc.). After all nodes have completed their share of the lines, they use a simple token-passing algorithm to output their lines one after another (Figure 7):
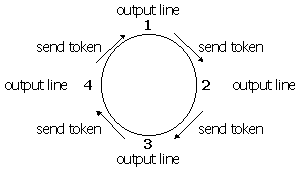
Figure 7: Token-passing synchronization
In this model, every node must wait to receive a token from its previous node before it can output a line. Then, it passes the token on to the next node, which has the next line of the image, and so on. Of course, one "master" node (the one that has the very first line) must initiate the cycle as described in the following pseudocode:
Master node:
compute all my lines
output my line
send token to next node
continue with WHILE loop as every other node
Every other node:
compute all my lines
WHILE NOT all my lines are output
wait for reception of token from previous node
output my next line
send token to next node
END WHILE
An obvious drawback of this approach is that only one node is busy outputting a line at any given point in time while all other nodes have to be idle, waiting until it is their turn. Processing power is further wasted by the fact that all nodes have to finish computation before the output cycle begins.
However, this drawback only exists if we use blocking communication, i.e. if a node can not execute any other commands while it is waiting to receive a message. If we use non-blocking communication, the node can initiate the reception of a message at some point in time, then continue working on other things and just occasionally check if a message has arrived. hus, if we use non-blocking communication for synchronization, the nodes can start outputting lines earlier and continue computation while it is not their turn to output a line, as described in the following pseudocode:
Master node:
compute my first line
output my first line
send token to next node (non-blocking)
continue with non-blocking reception as every other node
Every other node:
initiate non-blocking reception of token from previous node
WHILE NOT all my lines are output
IF NOT all my lines are computed
compute my next line
END IF
IF token received
output my next completed line
send token to next node (non-blocking)
initiate non-blocking reception of token from previous node
END IF
END WHILE
Here, each node checks after the completion of every line if it is has received a token. If that is the case, it outputs the line, passes the token on, gets ready for the reception of the next token, and then continues to compute the next line. If a line is completed but no token has been received in the meantime, the node just goes ahead and computes the next line, and so on. This means that a node can finish the computation of all lines before it has finished the output of all lines. In that case, it will output the remaining lines as soon as the respective tokens arrive, just sitting idle between tokens.
One might argue that it would be better to check for an incoming token more frequently than only after each completed line (which might actually be quite a long time for high iteration maximums). However, checking after every point (or even after every iteration), produces considerable overhead that slows the calculation down. In addition, there is not really any performance gained by outputting a completed line and passing the token on as soon as possible, since we are not wasting many ressources when we let lines accumulate: If the load is balanced relatively evenly, the final phase where some nodes are idle between communications should not be too long since all nodes need about the same time to compute all their lines.
The algorithm seems to work fine in theory: Each node computes its lines as fast as possible, and outputs them as soon as they can be under the in-order requirement. However, when we implement the algorithm and run it on a parallel processing cluster, we still observe that the lines in the output file are out-of-order:
PE0 started up on summit5
Maximum iterations: 150
Output size: 64 x 48 points
Top-left corner: (-1.78, 0.96i)
Bottom-right corner: (0.78, -0.96i)
Number of PE's: 4
Rows per PE: 12
PE1 started up on summit4
PE2 started up on summit3
#
PE3 started up on summit8
#####
#####
# ######## #
#####################
##########################
########### ############################
## ############
########################
# # ###########################
########### ###########################
#####
################## ##
########################
###### ###########################
# ######################################
##
###
######################
###########################
######### ###########################
## ######################################
######### ###########################
###########################
######################
###
# ######################################
###### ###########################
########################
################## ##
########### ###########################
# # ###########################
########################
## ############
## ######################################
########### ############################
##########################
#####################
# ######## #
##
Computation walltime: 0.086407 seconds
#####
#####
#
#####
|
Figure 8: Output of token-passing synchronization algorithm
To find the cause for this effect, we add debugging information to the output. In addition to the ASCII image, each node (process entity, PE) also prints out a line when sending and receiving a token. The value of each token consists of the PE number times 100, plus the number of the line was just output. For example, token 205 is sent by PE2 after outputting the fifth line in its share of lines (since PE's are numbered starting with 0, token 1 is sent by PE0 after outputting its first line). With this debugging information, we get the following output file:
PE0 started up on summit5
Maximum iterations: 150
Output size: 64 x 48 points
Top-left corner: (-1.78, 0.96i)
Bottom-right corner: (0.78, -0.96i)
Number of PE's: 4
Rows per PE: 12
PE2 started up on summit3
PE0: recv 0
PE1 started up on summit4
PE3 started up on summit8
PE0: send 1
PE0: recv 301 #####
PE0: send 2
PE0: recv 302 # ######## #
PE0: send 3
PE3: recv 201 ##
PE3: send 301
PE3: recv 202 ###
PE3: send 302
PE0: recv 303 #####################
PE0: send 4
PE0: recv 304 ##########################
PE0: send 5
PE3: recv 203 ######################
PE3: send 303
PE3: recv 204 ###########################
PE3: send 304
PE1: recv 1
PE1: send 101
...etc...
|
Figure 9: Output of token-passing synchronization algorithm with debugging information (truncated)
Stepping through the beginning of the output file shown in Figure 9, we see that the very first line output by PE0 is prefixed "recv 0", indicating correctly that no token was received before. Then, it sends token 1 ("PE0 just output line 1") to PE1, which is exactly what it is supposed to do. But next, PE0 immediately receives token 301 ("PE3 just output line 1"), which was not even sent yet, according to the output file. Obediently, PE0 outputs its next line, although it seems clearly out-of-order, then sends token 2. However, instead of the expected "PE1: recv 2", we then see that PE0 receives the next token (302) from PE3 already, outputs the respective line and sends token 3. Only now do we get a word from PE3, announcing it received token 201 and output its first line – which is not sent until much later, according to the output file. And then, finally, we see that PE3 sent token 301 as it was supposed to do. The output file continues in a similar unpredictable fashion until all lines are output.
Examining the output file more closely, we see that all nodes actually do exactly what they are supposed to do: They output the next line only when they receive a token from their precessor, and then send a token to their successor. Every node sends and receives the correct tokens, and outputs the correct lines. The only problem is that the tokens seem to arrive in the wrong order, being received before they have been sent.
The reason for this effect is subtle: As we can see, every node obediently outputs a line only after receiving the respective token from the previous node. So, the nodes indeed perform their output operations sequentially and in-order. However, the nodes have no control over how their individually output lines are collated in one overall file. Through buffering and delays introduced by the parallel processing environment, the overall output file is still being pieced together in chunks that may be larger than one line per node, thereby garbling the output order of lines.
< Output Synchronization | Polling Synchronization >

